See It In Action
A beautiful, intuitive dashboard for all your AI monitoring needs
Dashboard
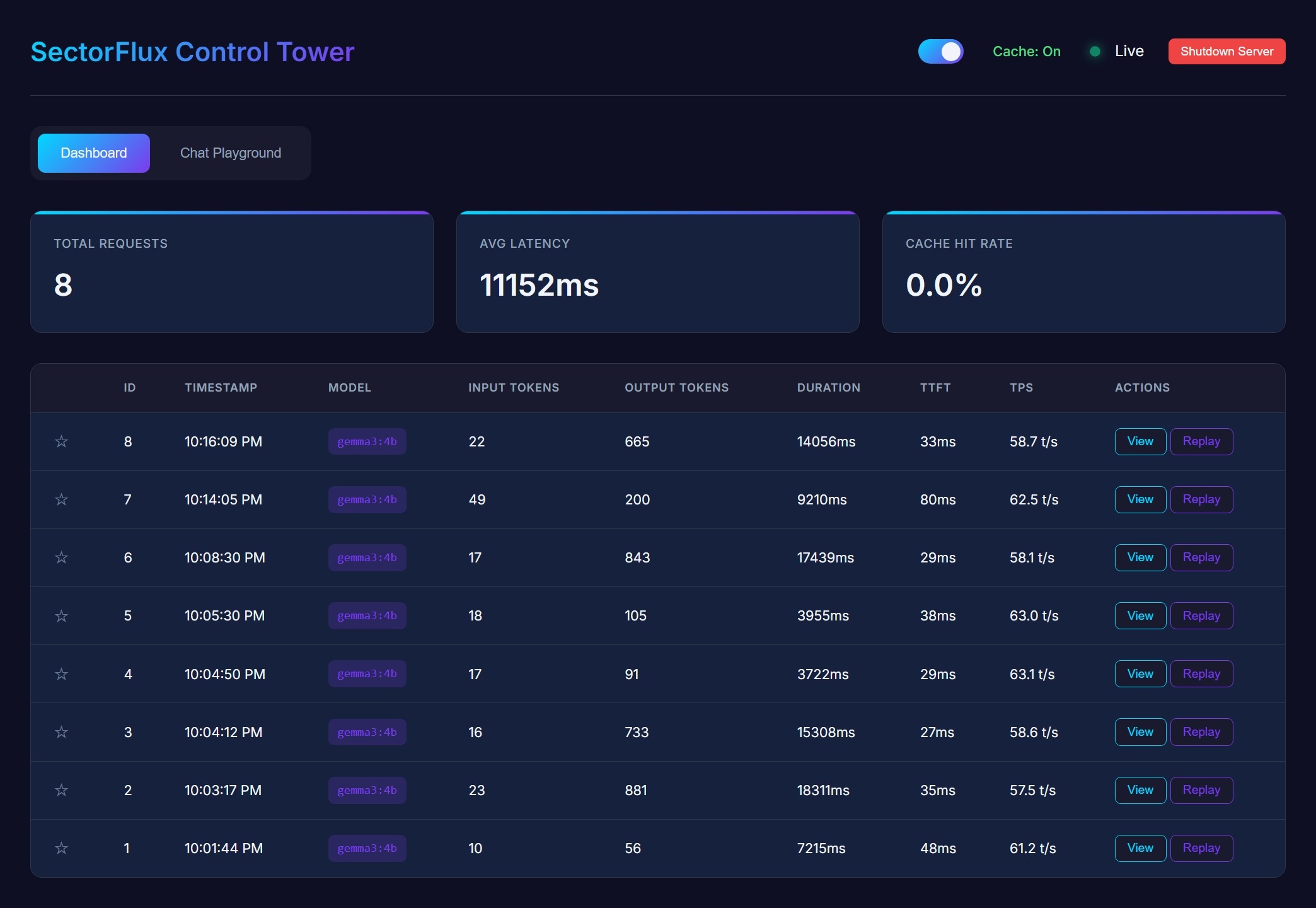
Real-time metrics and request history at a glance
Chat Playground
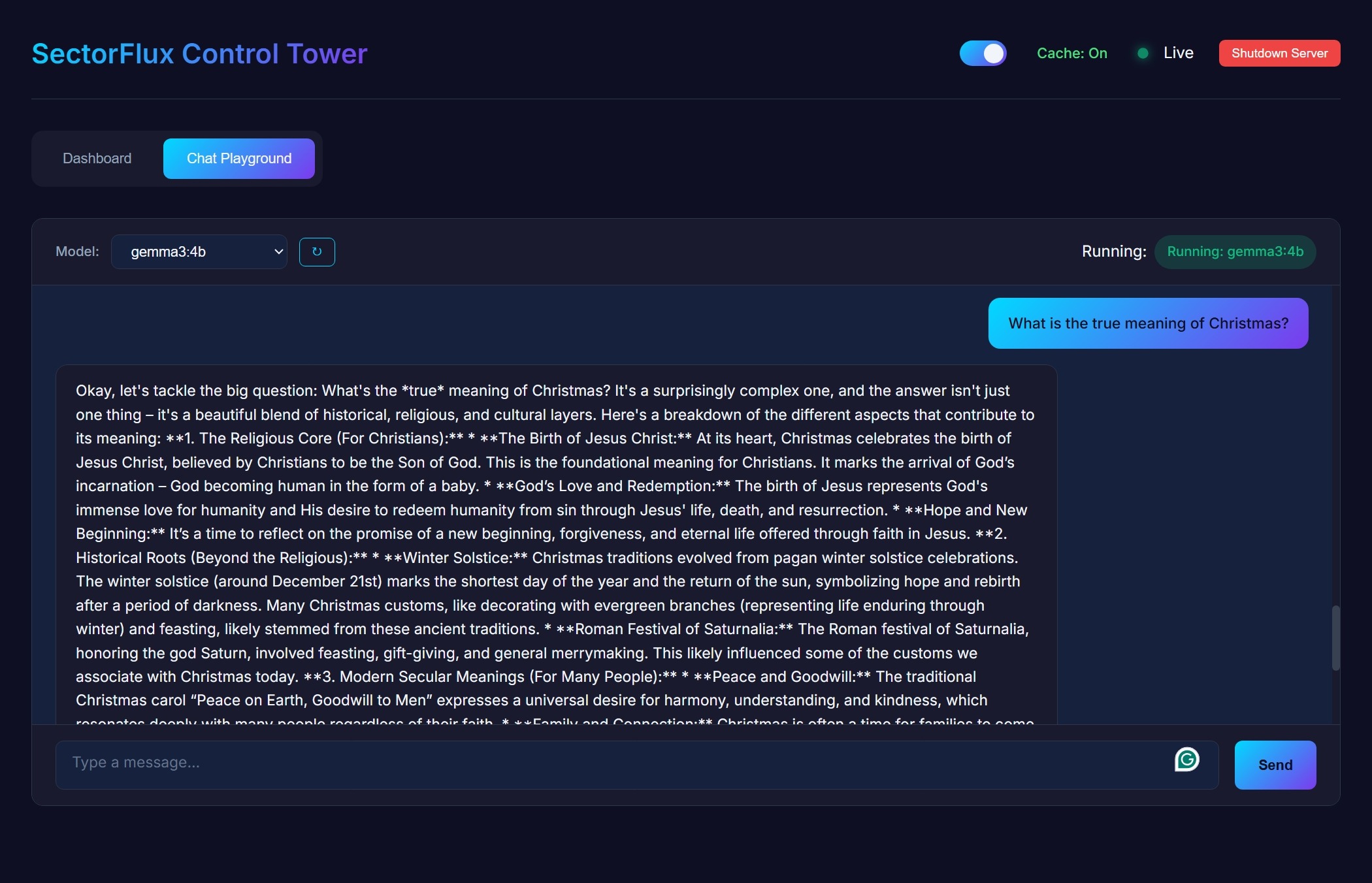
Test your prompts directly from the interface
Monitor, Debug, Optimize Your Local AI
A lightweight, high-performance flight recorder for local LLM agents. See every request, measure every token, debug every issue.
Open source under GPL-3.0 | Single binary, no dependencies
Powerful features for debugging and optimizing your local AI agents
Transparent forwarding with live token streaming. Your apps work exactly as before.
Complete history of all LLM interactions. Never lose a conversation again.
Token counts, latency, TPS, and time-to-first-token. Know exactly how your AI performs.
Optional response caching to reduce redundant API calls and speed up development.
Test prompts directly from the dashboard. No need for external tools.
No dependencies, no Node.js, no Python. Just download and run.
Just change your port from 11434 to 8888
# Your existing code
client = OpenAI(
base_url="http://localhost:11434/v1",
api_key="ollama"
)# Just change the port!
client = OpenAI(
base_url="http://localhost:8888/v1",
api_key="ollama"
)That's it. Your dashboard is now live at http://localhost:8888
A beautiful, intuitive dashboard for all your AI monitoring needs
Real-time metrics and request history at a glance
Test your prompts directly from the interface
Be the first to know about updates and Pro launch
No spam, ever. Unsubscribe anytime.